上一篇中提出的缓存方案,是解决对于数据库查询的压力,那么读写分离同样也是解决数据库读压力的一种手段,同时也解决了写压力。当单台数据库提供服务时,单表数据量达到千万以后,查询性能就会下降,特别是对于跨表查询的SQL,另外写和读都在同一台数据库服务器上,对于资源的消耗也是非常大的。
Runnf的写是22224,读是83328,综合下来是10万左右,数据库的配置是8核32G,这样单台Mysql服务器一般QPS可以达到15000的样子,所有这种规模下,单台肯定是不够的,我们首先在通过读写分离来分开写和读同时对于数据库的压力,当然,单台数据库能力目前也是无法提供我们整个系统写压力的(TPS为22224),这个是后面要讲的内容。
读写分离的场景
这里的读写分离也叫做主从架构,而不是主备,这个是有区别的,主从的意思是数据库主服务提供写操作服务,而从服务器提供读操作服务;主备的意思是主继续提供读写服务,而备服务器只是用来做备份,主服务器出现问题时备份数据库才提供读写服务。另外,主从架构的数据量在主和从服务器上是同样的,而不是数据分片,主从的架构如图所示。
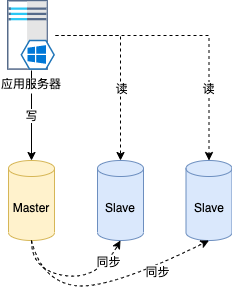
Runnf的读写比例为4:1,所以主从架构很适合这种场景,我们设计的主从架构是一主2从,写入数据到主数据库服务器,所有的读取操作在2个从服务器上。
读写分离的实现机制
可以在代码层面进行读写机制的实现,即封装一层API在DAO层,根据具体的业务逻辑实现读写分离,对于上层业务层来说完全透明,这种机制自由度比较大,甚至可以根据配置的形式,不同的业务配置到不同的库中,但是这种机制风险也比较大,一旦出现问题会导致数据库压力增大,需要人工去干预这种风险。如Mybatis的plugin机制,可以实现根据SQL语句是读还是写去获取不同的数据源进行操作,现成的有dynamic-datasource,以及Sharding-JDBC等。
另外一种实现机制可以通过中间件方式独立部署,应用程序访问数据库只要访问该独立部署的中间件即可,真实的数据库对于应用来说完全透明,这种中间件比较复杂,因为需要拥有完全的标准SQL解析能力,还要维护数据库的连接等,如Mycat,这种中间件一般是有实力的大公司才会研发。
Runnf采用dynamic-datasource来实现读写分离机制的实现,通过注解直接在业务层获取不同的数据源。
数据复制延迟
Mysql使用binlog数据复制机制,当数据库压力增大时,也有延迟现象,对于Runnf来说,因为缓存机制可以保证重要的数据写入数据库后即可通过缓存读取到,而且即使有一定延迟也不是那么敏感了,但是对于读取时效性要求高的应用,就需要考虑这个问题,比如,注册用户后,马上登陆,发现无此用户,这种情况,可以考虑在读取主库一次,或者重试从库2次后在读取主库,这2种机制,具体看应用的场景,比如一些关键的场景要求立刻读取到,那么就可以读和写都走主库,而非关键的场景按照读写分离来区分。
总结,Runnf这种读写比例4:1的场景,适合读写分离,读写分离架构为主从架构,不是主备架构,有2中实现机制,封装API和独立部署中间件,另外,数据延迟问题,通过缓存,场景区分来避免延迟。